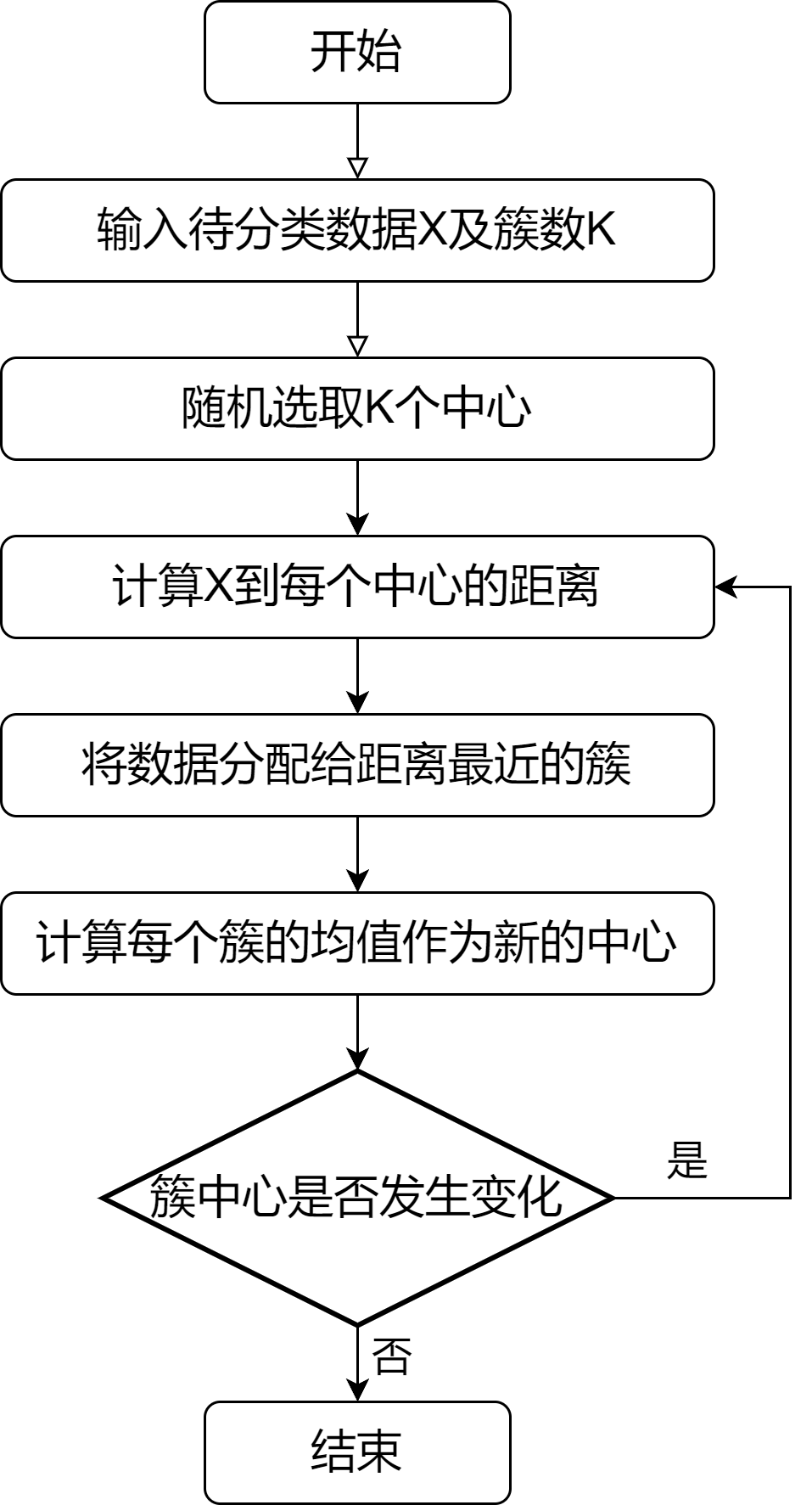
K-means聚类算法原理
0 前言 聚类是数据处理中常用的分析方法,此处简单介绍下K-means聚类算法原理。 1 K-means算法 1.1 算法简介 K-means标准算法是1...
-
 1146
1146
 0
0
 0
0
-
 工作学习
工作学习